在深度学习入门阶段,我们不可避免的会遇到如猫狗大战、验证码识别这样经典的题目,为了牢固深度学习入门的基础,特此写本篇验证码破解学习的总结。
** 本文基于 Keras 2.0.4 编写的代码 **
我们本次学习需要识别的验证码规则如下:
- 3 个运算数:3 个 0 到 9 的整型数字;
- 2 个运算符:可以是+、-、*,分别代表加法、减法、乘法
- 0 或 1 对括号:括号可能是 0 对或者 1 对

这次破解的验证码的难度属于初级,只需要喂足够量的数据即可达到 90% 及以上的准确度,利用下面的 CTC Loss 可以达到 99.9% 及以上的准确度。
这次的验证码属于不定长的验证码,我们只需要按照验证码的最大长度作为输出数即可,在此的输出数是 7 。
训练数据下载地址: -> 戳我下载 <-
0x01 载入训练样本
本文代码从 Jupyter Notebook 的笔记中截取下来
| |
上面代码是开始的初始化,n_class + 1 是加多一个空白符的意思。
180 和 60 代表着训练图片的尺寸大小。
| |
上面代码的 decode 函数就是对编码后的结果进行解密,而 get_data 就是加载训练数据,至此我们的前戏做好了。
0x02 CNN
| |
我们非常简单暴力的将图片塞进去,训练大概 25 个 epoch 就有 0.98 x 接近 0.99 的结果,模型结构如下。
模型可视化
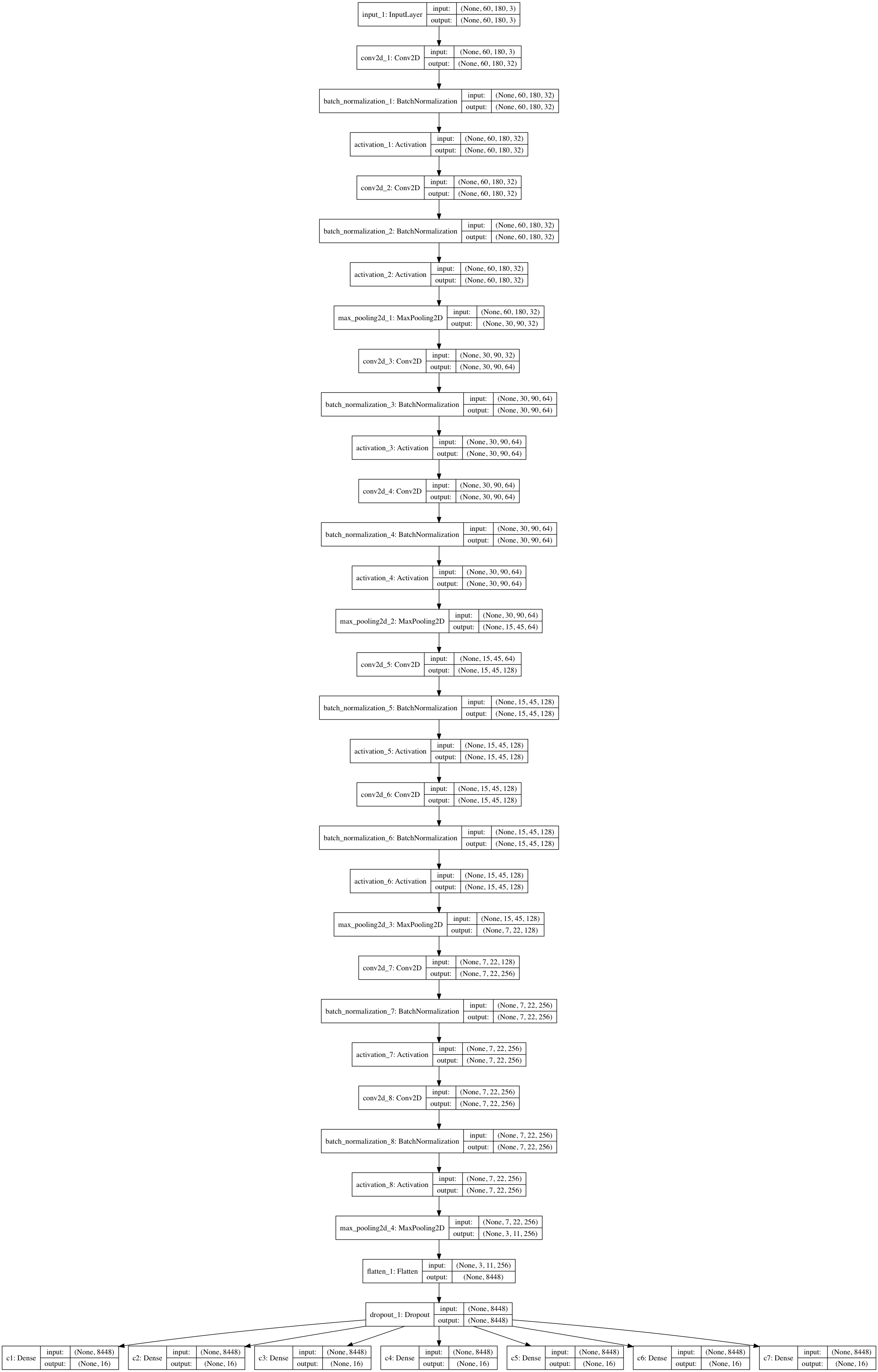
如果我们还想再继续提升,那么就需要换一种方法实现了,下面我们将使用循环神经网络来提升我们识别的准确率。
0x03 CNN + CTC
CTC ( Connectionist Temporal Classification ) 作为一个损失函数,用于在序列数据上进行监督式学习。
CTC Loss 是一个特别神奇的 loss,它可以在只知道序列的顺序,不知道具体位置的情况下,让模型收敛。
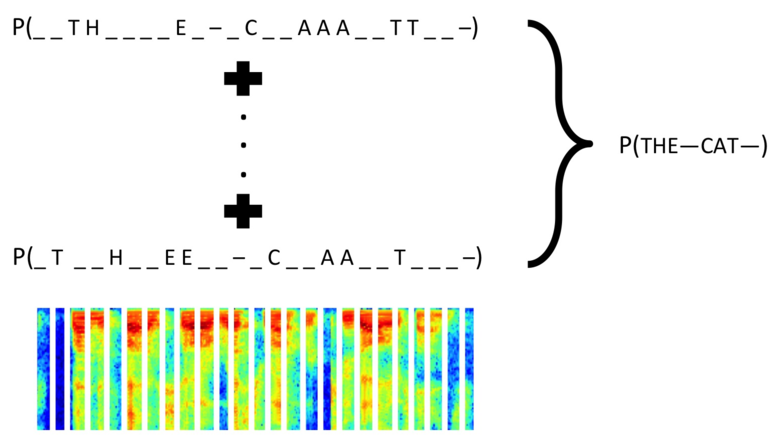
由于在 Keras 里面已经内置了 CTC Loss,我们只需定义如下的一个函数即可实现 CTC Loss。
又因为我们使用的是循环神经网络,所以默认丢掉前面两个输出,因为它们通常无意义,且会影响模型的输出。
- labels 是验证码,是 7 个字符(数字或符号);
- y_pred 是模型的输出,是按顺序输出的 16 个字符的概率,因为我们这里用到了循环神经网络,所以需要一个空白字符的概念;
- input_length 表示 y_pred 的长度,我们这里是 20(22-2);
- label_length 表示 labels 的长度,我们这里是 7。
实际上 label_length 应该填写不定长,但是这里的验证码复杂程度比较低,影响不是特别的大。
| |
模型结构的设计大致是,卷积神经网络识别特征,然后通过一个全连接降维,最后再按水平顺序输入到一种叫 GRU 的特殊循环神经网络。
按照培神的文章,在工程实践中我们发现 GRU 比 LSTM 好,所以我们在此采用了 GRU 。
| |
模型可视化
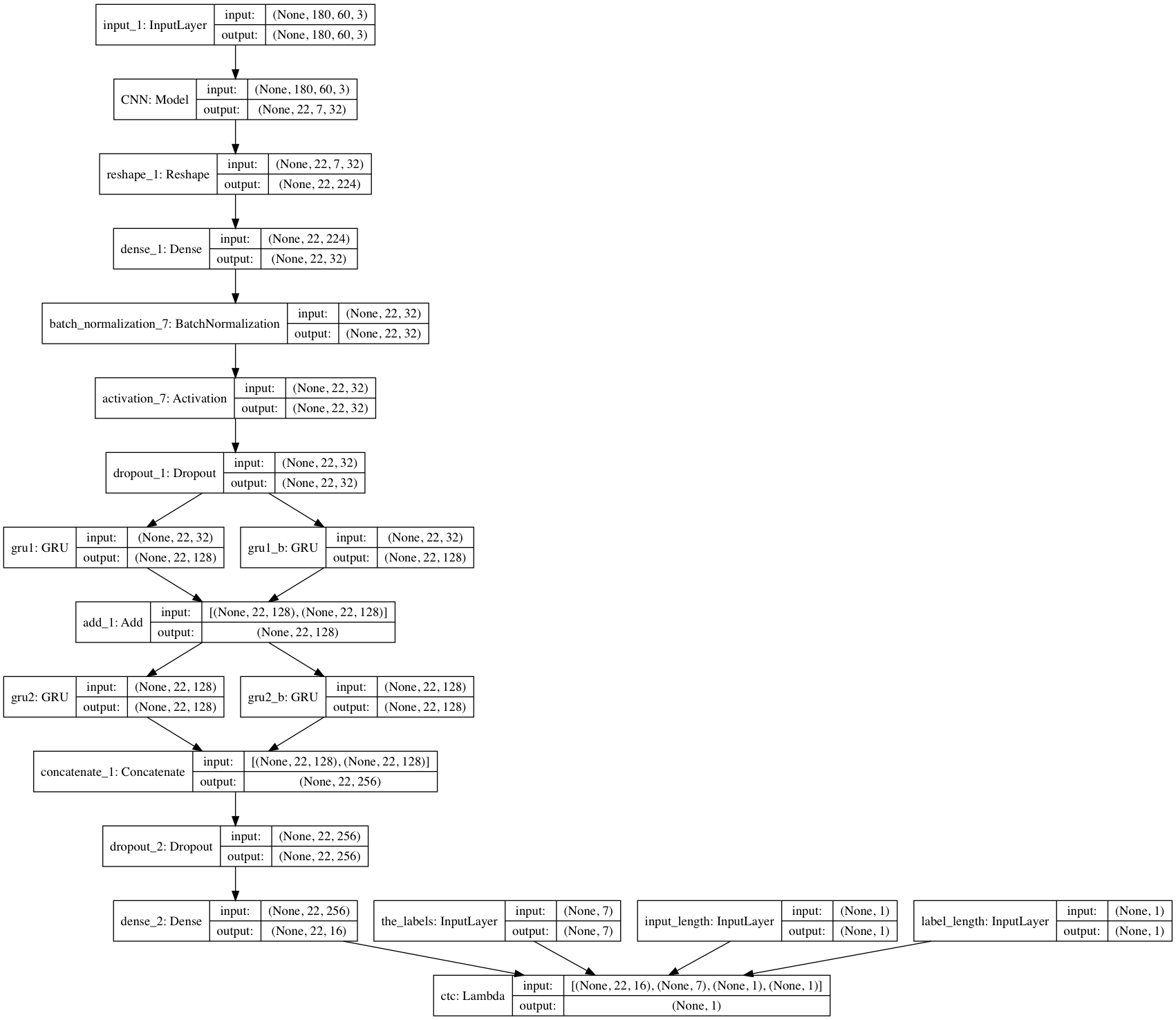
对比上一个模型,我们现在的模型明显复杂了许多,但其实只是输入变多了。
唯一需要注意的一点就是我们图片的输入,在上面卷积的时候用的是 numpy 的默认格式,即 (height, width, 3),而我们的 CTC 变成了 (width, height, 3) 。
这是因为我们希望以水平方式输入,然后经过各种卷积核降维变成 (22, 32),这里的每个长度为 22 的向量都代表一个竖条的图片的特征,从左到右,一共有 32 条。
然后我们兵分两路,一路从左到右输入到 GRU,一路从右到左输入到 GRU,然后将他们输出的结果加起来。再兵分两路,还是一路正方向,一路反方向,只不过第二次我们直接将它们的输出连起来,然后经过一个全连接,输出每个字符的概率。
使用 CTC Loss & CNN 的模型,最后的准确率可以达到 99.989% ,当然还有可能继续提高,限于时间关系就没有继续跑了。
然而,在现实应用中,达到 99% 就已经算是完全破解了这个验证码,也就是说这类型的人机验证已经失效了。